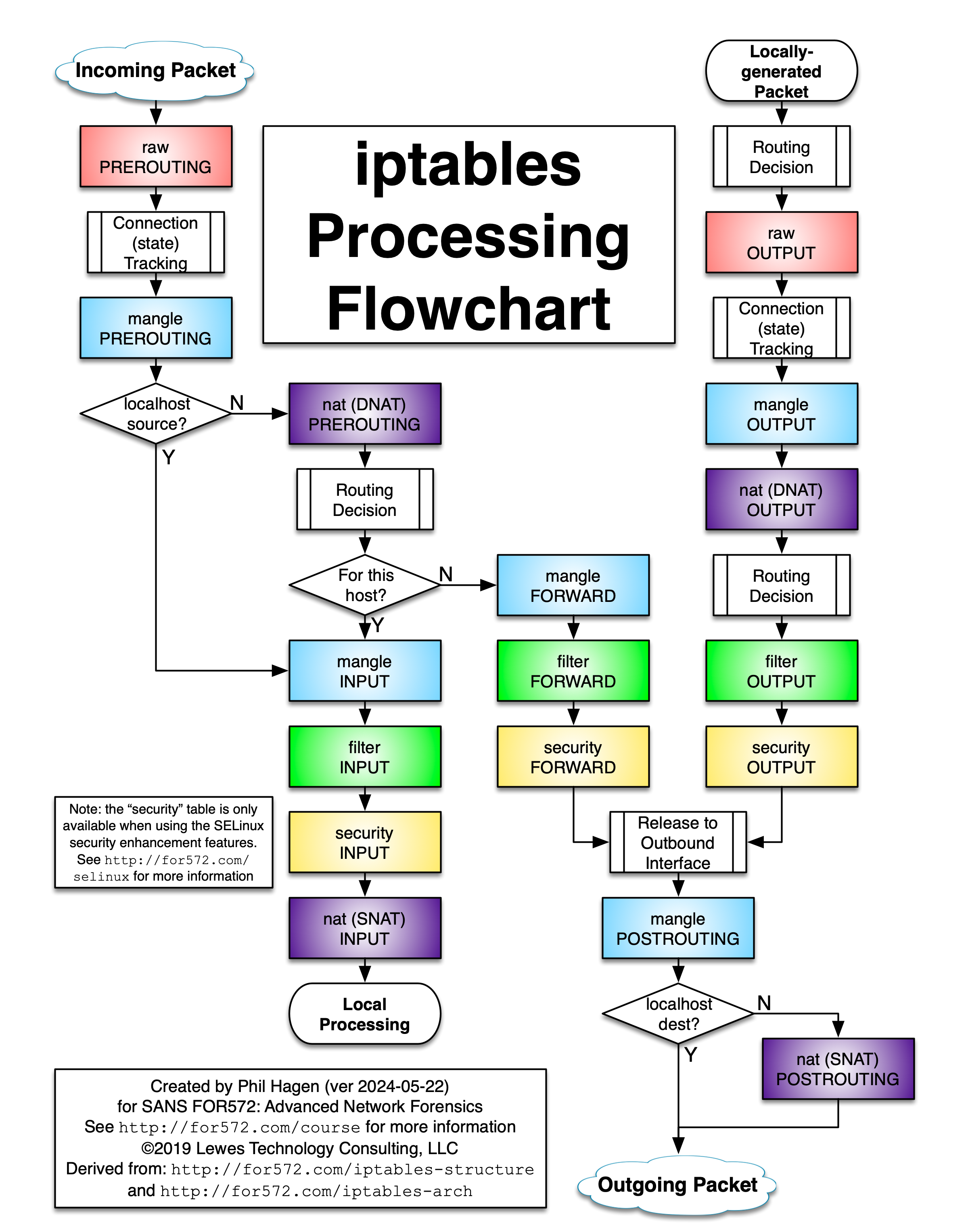
Many years ago, I started work with iptables, the Linux-based firewall software. At the time, documentation was sparse, and the details about what happens to a packet during processing were hard to figure out.
Since then, documentation has improved, but I always wished there was a visualization that I could quickly use to trace a packet (observed or theoretical) through the various tables and chains. While creating content for SANS FOR572, Advanced Network Forensics: Threat Hunting, Analysis, and Incident Response, I decided to create a flowchart myself. Since I find it most useful in color, I’ve provided the document here.
Updates:
- 2024-05-22: Added DNAT/SNAT annotations for all nat tables.
- 2019-04-30: Added the three chains on the SELinux “security” table; added additional routing decision points for locally-generated packets; added reference to a great Linode post on newer functionality. Thanks to commenter Diego for the suggestion on adding the security table!
- 2018-11-14: Reflects that outbound interface is determined by routing decision, not iptables.
- 2018-09-01: Reflects that localhost-sourced/destined packets will not traverse the nat table’s PREROUTING/POSTROUTING chains, respectively. Thanks to commenter Binarus for the pointer.
- 2017-03-30: Thanks to commenter Eike for noting that some terminology with the outbound interface selection was unclear.
- 2017-02-01: Thanks to commenter arm for noting that newer kernels also provide a NAT|input chain.
- 2016-11-18: Thanks to commenter Andrey for pointing out an error, which has been corrected. I’ve also adjusted the arrangement and cleaned up the logic a bit in this version.
I hope you find the document useful. If you have any input to make it better, please let me know.
Hi Phil,
Thanks very much for this excellent flowchart.
I have a question for the part that is only available in your flowchart between all the others that I found online. The section (decision) after the MANGLE PREROUTING which states “Localhost Source?”. How exactly is this determined? I have a weird situation where the NAT PREROUTING is skipped, i.e. according to your diagram my source IS localhost, only that it isn’t! The source is a locally hosted libvirt VM IP which is supposed to be unknown to the host. The VM(s) NICs are connected on a bridge, which has its own parent physical interface and forwards frames to a router which in turn forwards packets to the VM host’s IP in a separate NIC from the VM bridge. I would expect that this traffic will be DNATed (as I need to, to my internal k3s cluster net PODs) but the NAT PREROUTING chain is skipped and the initial SYN packet is sent to MANGLE/FILTER INPUT instead, never establishing a conntrack connection.
An interesting! I can’t say for sure with regard to your observations, but I’ve seen various virtualization layers throw the normal” process of things into question. For example, VMware’s hypervisor (in bridged mode) completely bypasses all netfilter functions on a Linux host. So it’s likely something along those lines is happening with your setup. You’d likely need to consult the libvirt code/team and whatever the underlying virtualization provider is.
Hi Phil
Thanks for this useful flowchart!
The Wikipedia article on iptables says, of the PREROUTING chain, “Packets will enter this chain before a routing decision is made.” That implies all packets. But your flowchart says it is only incoming packets. Which is correct?
There are a couple of similar points on the Wikipedia article. I suspect your flow chart is probably correct.
Also, does each table contain (at least) the 5 predefined chains, albeit some possibly empty?
Thanks
Thank you! Glad you find this helpful. You’re correct that a locally generating packet does not traverse a PREROUTING chain on any table. There is no need to make an “is this packet for this host?” decision on these, as they’re being transmitted elsewhere. However, if that packet is sent *to* the same host, it will later arrive as an incoming packet, therefore traversing those tables/chains before local processing. I don’t want to get too far down the rabbit hole of nuance in the Wikipedia article, but I am confident that this diagram should still be accurate with the later versions of the Linux kernel.
With regard to the chains on each table, not every table has all five chains. For example, the “raw” table has “PREROUTING” and “OUTPUT”. The “filter”, “security”, and “nat” tables also do not have the full set of chains.
Hey wow, this is such a precious diagram, thank you so very much for creating it. Just an opinion, It would be great if it also referred where DNAT and SNAT are happening.
Thanks – I’m glad you found this useful! Great idea on the DNAT/SNAT addition. I’ve just made the update now.
This is great resource thanks.
I am struggling with one simple question – is there a failover mechanism that exist in the routing? For example – in a multi homed server(imagine – 2 NICs with different IPs in different subnets and each having its own gateway) will be able to identify which NIC to use to reach a destination that is reachable only via (say) NIC1? If it chooses (say) NIC1 whereas the right decision is NIC2, can I somehow make the kernel failover and upon ICMP network unreachable message, the system doesn’t give up but tries the other NIC? This is important when you are trying to initiate connections (not as a router but for outgoing connections). Thanks
Hi, Manish – glad you found the diagram helpful! The behavior you describe is not part of iptables or iproute2, but is provided by a failover setup for high availability networking. It’s been a long time since I configured this myself (and then, only in an experimental capacity), but you may find this resource helpful: https://www.howtoforge.com/tutorial/how-to-configure-high-availability-and-network-bonding-on-linux/
Thank you, Phil. Unfortunately it’s not about load balancing or failover but trying to reach two different and distant networks via two independent gateways from a single system. I am still looking for some help 🙁
It’s been some time since I researched and wrote about iptables, however IIRC, you can only have one true (Internet) gateway.
That said, you should be able to use NAT rules to create some sort of pseudo-load balancing. For instance, that’s essentially how a “split VPN gateway” functions. Certain traffic is routed over the VPN to the Internet, and other traffic is routed through a local gateway. Which traffic goes where is dependent on ‘tagging’ each packet and then filtering by the tags (sort of like how some routers filter traffic via VLANs).
You may find some pertinent info here: https://datahacker.blog/industry/technology-menu/networking/routes-and-rules/introduction-to-split-gateways
I was trying to figure out the order of mangle/INPUT, filter/INPUT, and nat/INPUT. I am pretty sure your diagram is correct having looked through the netfilter source coude. However, the Wikipedia article seems to be wrong. The diagram here https://upload.wikimedia.org/wikipedia/commons/3/37/Netfilter-packet-flow.svg puts nat/INPUT in between mangle/INPUT and filter/INPUT, which disagrees with the priorities given in the source code.
The priorities are the same as stated in this page https://wiki.nftables.org/wiki-nftables/index.php/Netfilter_hooks, although I know that page is for nftables not iptables.
Am I correct? That Wikipedia is wrong on this and your diagram is correct?
Wow – congratulations on a spectacular find! At first review I agree with your statement that the SVG Wikipedia image is incorrect. I’d want to re-run some tagging/logging tests to confirm that but I’ve run them in the past and am confident in the order depicted in the diagram here.
Thanks! Could you explain how you’ll do the tagging/logging tests? I’d like to reproduce those tests myself.
I initially wanted to try to log a packet through the different tables/hooks to get a definitive answer (using -j LOG), but couldn’t 100% convince myself that entries in the log file would be in the order of the LOG rules matched by a packet as it passed through all chains.
So does the netfilter logging guarantee that if nat/INPUT is after filter/INPUT, then for a given packet ‘p’, a -j LOG rule that ‘p’ matches in chain nat/INPUT will be written to the log file after any -j LOG rule that ‘p’ matches in chain filter/INPUT?
That seems to be quite a strong guarantee, because it could require that appending to the log is a blocking operation.
If that’s not a guarantee of netfilter logging, is there another way to trace a packet through the chains?
Yes, that was my test methodology. However, you bring up an excellent point that the syslog logging order is not necessarily guaranteed. However, the dmesg timestamp refers to the number of seconds since boot – down to milliseconds. My understanding is that this timestamp is generated by the kernel at the time it is generated. It’s been some time since I ran the tests, but I recall that the dmesg timestamp order matched those from syslog (at least in order, if not exact interval).
hi,I want to know,what things “routing decision” do.
When I enable nf_log_ipv4:sysctl net.netfilter.nf_log.2=nf_log_ipv4,
I see a packet‘s IN and OUT changes:
#1 raw:PREROUTING:policy:2 IN=gre1 OUT=
#2 mangle:PREROUTING:policy:1 IN=gre1 OUT=
#3 nat:PREROUTING:policy:1 IN=gre1 OUT=
#4 mangle:FORWARD:policy:1 IN=gre1 OUT=eth0
#5 filter:FORWARD:policy:1 IN=gre1 OUT=eth0
#6 mangle:POSTROUTING:policy:1 IN= OUT=eth0
#7 nat:POSTROUTING:rule:1 IN= OUT=eth0
at #4,OUT get a value(eth0), it should come from “routing decision”,and indicates that the packet will out from eth0 interface finally,alright?
at #6, why dose the IN(gre) is disappeared?
it is caused by “Release to Outbound Interface”? What dose this means?
Thank you in advance.
Great questions – although maybe more in the vein of the Linux kernel’s routing behavior than iptables itself.
1. The output interface is known (between #3 and #4 in your list) after the kernel’s routing decision is made. You’re correct that this is why “eth0” is indicated from steps #4 and later.
2. The input interface is no longer tracked when it is not needed. I can’t fully answer why that happens when it does, but I assume it is because as soon as the packet is released to a destination/output interface, there is no further need to keep knowledge of where it came from.
I would suggest seeking out more detail from the linux kernel itself, though, as I’m not deeply familiar with the inner workings of that routing functionality.
Do you happen to know how that routing decision “for this host?” (right before the mangle table’s input chain) determines if the destination is actually “this host”?
For example, I have a machine which has two ethernet interfaces (say, A and B). Each interface has an IP address and these IP addresses belong to different networks. So, when a packet arrives on interface A, and that packet is destined for ip address B, does the decision logic (“for this host?”) recognize that ‘B’ is an address on the host? Or does the decision really only ask: is this packet destined for the ip address of the interface which received the packet?
That’s a great question – and I don’t have a definitive answer. My best (but totally speculative) guess is that the kernel’s network stack knows what its interfaces and their IP addresses are, and handles the packet internally when the destination is one of those. For example, if I run “ping” from one interface’s IP address to another on the same home, that packet never leaves the system. (e.g. If you have a tap/port mirror on the ethernet from the NIC, you won’t see that ping exchange.)
One way to test part of this theory would be to put what I call “tracer” LOG rules on each table+chain that you expect the packet to pass, using a unique “–log-label” flag on each. Then you can check the syslog output to validate which chains processed a generated packet. If you do this, I recommend using command-line options on “ping” to send one only – the logs get REALLY chatty really fast. Plus, you can then craft the LOG rules to match only ICMP traffic, keeping things nice and clean.
Thanks. I inserted LOG rules at top of all the chains in all tables, and indeed the packets described above only made it through the Filter input chain, and they only logged once. So, with that I think we can conclude that you are right that the kernel knows all the IP addresses it has. Thanks!
Actually, I described that incorrectly: I didn’t add LOG rules to any pre-routing chains in any table no to Mangle input.
great approach – and sounds like it operated as expected! Thank you for following up with the test results!!
Thanks for preparing the diagram, it was *the* source I needed to debug an issue with iptables.
Hint: the PNG file has transparent background which may render as black when opened in a browser. So if after opening it all you see are boxes on a solid black background, download it and “
convert -flatten chart.png chart-fixed.png” to make the background white 🙂I’m glad you found the diagram useful!
Thank you as well for the suggestion on re-coloring the PNG file – that will allow anyone’s preference on the file. Great idea!
can explain curl 127.0.0.1 traffic loopback, it pass throught prerouting or postrouting
Loopback traffic would start at the “Locally-generated Packet” step, progress through the “Outgoing Packet” step – but the outgoing interface would be
loor equivalent. Then, the packet would be picked up at “Incoming Packet” and process through the “Local Processing” step.thanks.
can you explain “Locally-generated Packet” to the outgoing host, why don’t progress through “PREROUTING” chain, maybe this packet need DNAT.
Any packet generated by a local process – whether and originating session or a response – follows the pipeline starting at “Locally Generated Packet”. Therefore, you cannot adjust the destination IP address for these packets using the netfilter modules, as there is no table+chain that packet will traverse that allows the DNAT action. Since the routing decision is made first (by the IP stack), no further destination manipulation can be done.
thanks for your reply.
But, I check all the hook , the nat table + OUTPUT cahin allows the DNAT action.
Maybe you can do a little test.
Ah yes – nat/OUTPUT does allow that now. Hence the second routing decision. That table+chain is reflected in the table as well.
Do you know if nftables shows the same behavior/processing like iptables does in your Flowchart?
It’s a bit difficult to compare them directly like that due to some substantial differences in their operation. For example, there are no pre-defined chains and no-predefined tables in nftables, yet it does have pre-defined processes that sound similar (e.g. PREROUTING). IMHO, it’s confusing at first for iptables veterans because the terminology does not carry over 1:1 per se.
nftables seems to try and group commands by function versus by sequence (what iptables does). It seems the idea is to combine into nftables the functions that were called by multiple indpendent tools (e.g. iptables and ip6tables).
You may want to checkout these (very high level) process flow maps here: https://wiki.nftables.org/wiki-nftables/index.php/Netfilter_hooks
Continuing with my example above, there is still a PREROUTING process in some nftables charts, but it’s not a chain. So, as a long-time iptables user, one tends to think “What is that? A chain?” No, it’s just informing you of the current position of the packet as it is traversing IP packet processing.
Another related example of their differences…. nftables uses table “types” or “families” which are ip, arp, ip6, bridge, inet, and netdev. Overall, it’s really comparing apples to cucumbers. The tools are quite different.
Re-capping… the big diffs between iptables and nftables are nftables has:
– no built-in or default chains or tables
– all tool “families” combined into a single tool
– new kernel sub-system that allows some new features (e.g. built-in data sets)
– theoretically easier to scale (YMMV) vs. iptables
No wonder nftables adoption has lagged since it was introduced. Those of us who have been writing iptables rules for a long time really don’t have a lot of good reasons to move, quite frankly.
Great question and thanks very much to @David for the details. I agree it’s a confusing shift from those who know iptables at any level to get a good idea of what nftables does differently and how to translate from old iptables syntax to nftables.
I’ve started the very preliminary stages of a diagram after you posted the comment, but after a few hours of research and testing, it’s going to be quite difficult to create a parallel diagram. The simple hook ASCII art that David linked is a start, but there are a lot more nuances than appear in the diagram.
I can’t project when anything may be ready for release, but I’ll make a note of it here if/when it is.
Why do the counters not seem to reflect chain traversals? I’ve been trying to figure this out for years, and the counter behavior is apparently not a well understood topic.
Here’s my current output for the “incoming packet destined for local processing”. Everything was zeroed out at the same time. Why are the 8116 packets in “nat PREROUTING” not shown for “raw” and “mangle PREROUTING”? Also, why do the number of “new connection” packets in the “filter INPUT” chain (rules 2-4) not equal 8116? (They almost do, though). Note: “mangle FORWARD” and “filter FORWARD” both show “0 packets”.
The script I used for visualization purposes is at the bottom.
raw
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
mangle
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
nat
Chain PREROUTING (policy ACCEPT 8116 packets, 631K bytes)
pkts bytes target prot opt in out source destination
mangle
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
filter
Chain INPUT (policy DROP 2296 packets, 120K bytes)
pkts bytes target prot opt in out source destination
15899 2500K ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
4979 406K DROP udp -- * * 0.0.0.0/0 0.0.0.0/0 multiport ports 137:138
787 258K ACCEPT udp -- * * 0.0.0.0/0 0.0.0.0/0 udp spt:67 dpt:68
2296 120K LOG all -- * * 0.0.0.0/0 0.0.0.0/0 LOG flags 0 level 4
nat
Chain INPUT (policy ACCEPT 6 packets, 1968 bytes)
pkts bytes target prot opt in out source destination
The bash script:
#!/bin/bash
#
# display iptables chains in order of packet traversal
# see https://stuffphilwrites.com/2014/09/iptables-processing-flowchart/
CHAINS=(
"raw PREROUTING"
"mangle PREROUTING"
"nat PREROUTING"
"mangle INPUT"
"filter INPUT"
"nat INPUT"
)
show_iptables() {
local table=$1
local chain=$2
echo -e "${table}\n"
iptables -t ${table} -L ${chain} -vn;
echo
}
for chain in "${CHAINS[@]}"; do
show_iptables ${chain}
done
(edited your post for formatting)
You have a great question there and to be honest, I’m not sure what’s going on there. I never paid much attention to the packet counters for the default chain policy, as my configurations are typically set to
ALLOW, with explicitLOG+DROPrules at the bottom to handle things. All I might suggest would be to add rules on each of the preceding chains that match the traffic you want to count to see if that triggers the increase as expected.I’m interested in hearing your results – this is a very curious observation indeed.
Hey Phil. Thanks for adding the SECURITY table references. I had previously only been able to identify the hook for SELinux in the INPUT chain.
BTW do you have sources of the diagram somewhere on GitHub? I couldn’t find any.
I really liked the diagram and it helped me understand how iptables works.
But I found helpful to have an additional arrow like on this diagram which is based on yours (https://s3.amazonaws.com/cp-s3/wp-content/uploads/2015/09/08085516/iptables-Flowchart.jpg) – the dashed line from Local Processing to Locally Generated Packet.
I removed that line some time ago because not all received packets will result in a locally-generated response. The line was confusing for most people, as the received and sent packets are discrete events.
Also, there are no sources for the image, just the image itself.
CONGRATULATIONS!
The best datapath that I saw!
But I have a question…
After [mangle POSTROUTING], there is a . Why?
This decision is not taken in (between PREROUTING and INPUT).
Thank you.
Truthfully, I don’t know why that is. You may want to contact the kernel developers that contributed this code to get better detail on that.
Ok, I understand why…
Now I have a suggestion.
You could put the “security” table in INPUT, OUTPUT and FORWARD chains, after the table “filter”. This way, you would cover all iptables tables.
(REF: https://www.linode.com/docs/security/firewalls/control-network-traffic-with-iptables/)
It would be perfect!
It’s just a suggestion, of course…
Thanks for the suggestion and link. I rarely encounter systems with SELinux enabled, so I had left that out. But it’s a good suggestion and I’ve updated the document. I’ll replace that in the post in just a moment.
The flowchart says “Derived from http://for572.com/iptables-sructure“, but this link is broken.
This has been a problem for a while now – the site was taken down without explanation. However, I’ve just pulled a mirror from the Wayback Machine and hosted it myself. The short link has been updated (note the link is actually for572.com/iptables-structure). Thanks for the nudge to finally check this off the proverbial “to-do” list!
I just came to say. Thanks a lot for the helpful flowchart.
I always thought you would design the flow chart first then make the software – not the other way round. Then again what do I know.
Glad you finally got round to making this.
A fair statement – I’m of the same mindset!
Hi I try policy based routing and made one fwmark in filter FORWARD, after some ACCEPT and DENY in my firewall. Via ip rule matching this fwmark I try to make a routing decission. I can see that the fwmark is set and the rule is correct, but never used.
So I think there is no routing decision after filter FORARD.
If I set my fwmark in mangle PRERPOUTING it works.
Interesting observation – possibly a semantic/clarity issue on my mart. Additionally, the source documentation is ambiguous here. (Their diagram shows the interface routing decision is done after the filter|OUTPUT and filter|FORWARD chains, but tables 6-2 and 6-3 do not reflect this.)
I included that block and specified it was an “INTERFACE Routing Decision”, meaning the system determines what the output interface will be, but doesn’t make a full routing calculation. This interface determination is important, because the POSTROUTING chains will have access to the outgoing interface name for the “-o” flag in iptables.
I’ll update this to reflect that it’s an interface determination, not a routing decision, though. Give me a few minutes to update and publish.
Thanks for the observation and feedback!
The ruleset filter.FORWARD permits tests of the outbound interface (-o … ) as well as the inbound interface. The choice of output interface cannot therefore follow filter.FORWARD.
Thanks.
Ah – that’s an interesting nuance. The outbound interface is initially identified during the “Routing Decision” step. This is what’s used during the
-oevaluation on thefilter.FORWARDchain. However, since the packet is not released to an interface until after the various*.OUTPUTrules have been handled. I absolutely understand where the confusion comes from here and agree that perhaps the wording on “Outbound Interface Assignment” could be clearer – perhaps “Release to outbound interface”. I did try to mirror the upstream iptables documentation as closely as possible, though. I’ll flag this for clarification in the next update – thank you for pointing it out!A little problem with the chart:
Right after the locally-generated-packet and before the raw-output, I think there should be a routing-decision.
Am I right?
I don’t believe so but I’m looking into a few resources on this. The routing decision is made down the processing pipeline in the “Interface Routing Decision” box. I’m quite sure that the iptables/netfilter processing is all done before that step.
good chart, helpful, thanks.
It seems you are missing the nat INPUT chain.
Also, you are not showing a path for local packets with local destinations to take, which traverse OUTPUT and then INPUT.
Great catch on the NAT/INPUT chain. It seems this was not present in CentOS prior to version 7 (possibly 6 – don’t have a system to test at this moment). I’ll get all of the details on the placement within the flowchart nailed down and post an update here when it’s ready.
Some details on this are here:
– https://ubuntuforums.org/showthread.php?t=1874307
– http://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=c68cd6cc21eb329c47ff020ff7412bf58176984e
With regard to the local destinations, that’s not something I’d want to address in the chart itself, as it’s just a path from “Outgoing packet” to “Incoming packet” that doesn’t happen to leave the system’s memory.
Thanks for the great call on NAT/INPUT!
Just a note to mention I clarified two differences with localhost-to-localhost pathed packets
Thank you very much for that useful chart which helped me a lot and is the most accurate and up-to-date one I could find so far.
However, I think there is still an error. In response to zrm’s comment, you have stated that packets originating from and destined for the local machine (i.e. looped back packets) just travel the output chain first, then the input chain, and that you therefore don’t want to treat this subject explicitly in the graph.
As far as I can tell, this is not correct. Many years ago, I had problems with understanding some test results and therefore posted a message at the netfilter mailing list. The answer from Pascal Hambourg clearly stated that locally generated packets do not pass the nat PREROUTING chain, for example.
This means that packets which are generated locally and absorbed locally do *not* run through all input changes (and eventually not even through all output changes, but I don’t know for sure).
Therefore, I would be very grateful if you could update the graph so that it correctly reflects how purely internal packets are flowing.
The conversation at the netfilter mailing list is here:
https://www.spinics.net/lists/netfilter/msg47714.html
Please note that I might be wrong since it is 8 years later now. On the other hand, I strongly doubt that they have changed this because it just makes sense.
Aha – I see what was meant before and I appreciate the input. I’ve updated this to reflect two differences when handling localhost-to-localhost packets. (Note that the nat/POSTROUTING chain is not used for packets destined to localhost either.)
Thanks!
OK – updated on the page and download link. Thank you again!
Well, do not use it as a generic flowchart. It has two mistakes when compared to the source it was derived from.
Hello, Andrey – can you let me know what the errors are? This is based on a number of sources, and I believe it to be correct. However, if there are errors, I would very much like to fix them right away.
1. ‘filter FORWARD’ and ‘filter OUTPUT’ should merge not at ‘mangle POSTROUTING’, but at ‘routing decision’ (that is incorrectly placed between ‘nat OUTPUT’ and ‘filter OUTPUT’).
2. branching ‘For this host?’ is also a routing decision (or routing decision should precede it) .
Thanks for the update, Andrey. Great catch on the logic bug – fixed. I’ve also adjusted the logic flow a bit to (hopefully) be more coherent and straightforward.
Thank you, is really useful.